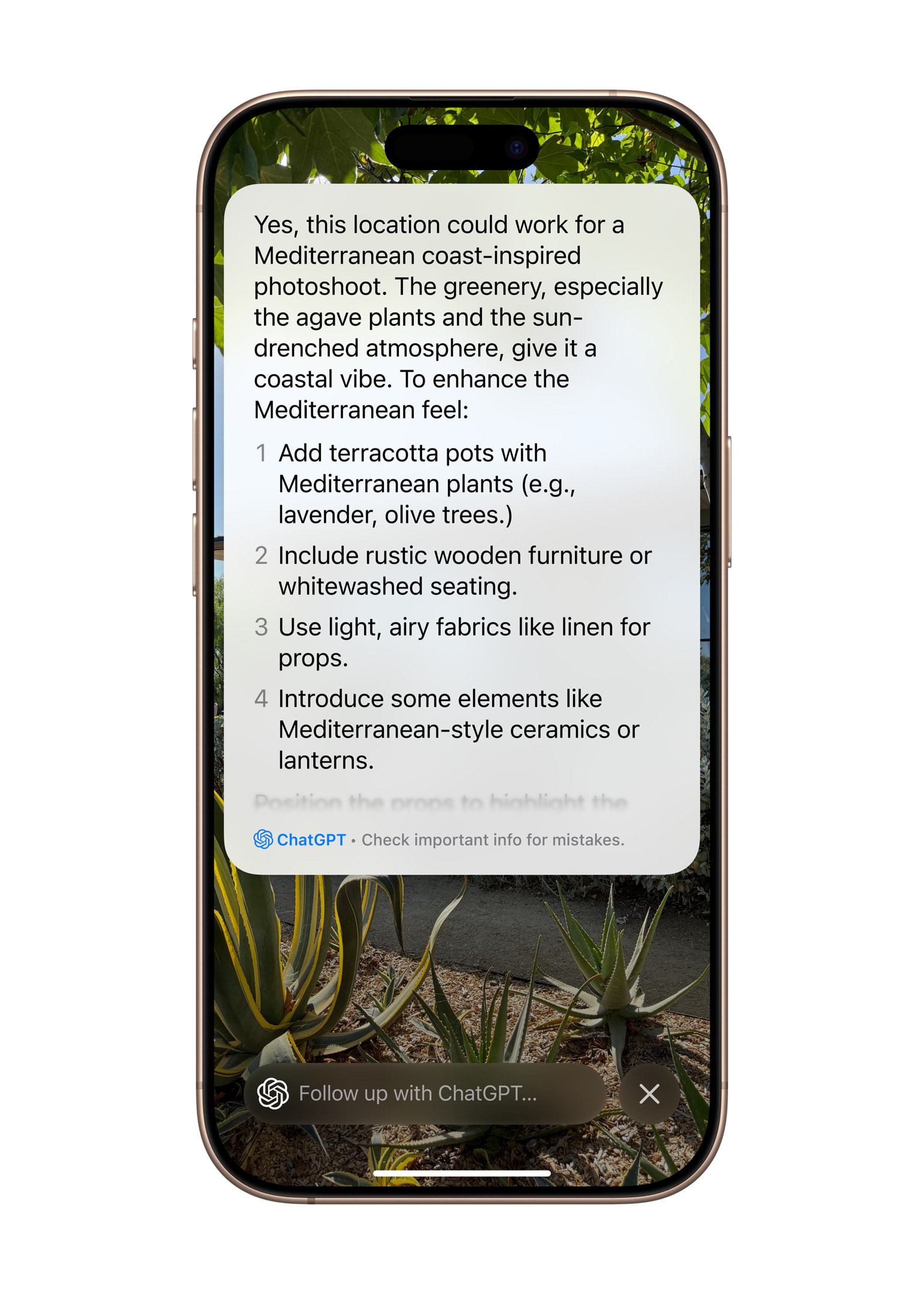
Not-so-smart smart bots
The research does show some strength in the models that are available today. For example, ChatGPT-4o still achieved a 94.9% accuracy rate in tests, though that rate dropped significantly when researchers made the problem more complex.
That’s good so far as it goes, but the success rate nearly collapsed — down as much as 65.7% — when researchers modified the challenge by adding “seemingly relevant but ultimately inconsequential statements.”
Those drops in accuracy reflect the limitation inherent within current LLM models, which still basically rely on pattern matching to achieve results, rather than making use of any true logical reasoning. That means these models “convert statements to operations without truly understanding their meaning,” the researchers said.








{kind=link}